Lendo dados.. aplicações com R e Python
Saldo de emprego Distrito Federal

Photo by Christopher Burns on Unsplash
O Cadastro Geral de Empregados e Desempregados (CAGED) é um registro mensal da criação e encerramento de empregos formais no Brasil. A cada mês as empresas enviam ao Ministério do Trabalho e Emprego (MTE) os registros de admissões e desligamentos ocorridos, junto com essa informação são enviadas outras como: salário mensal, quantidade de horas contratadas, tipo de contratação, tipo de desligamento, ocupação, atividade e etc. Portanto, a CAGED fornece muitas informações para analisar o mercado de trabalho formal no Brasil.
Mensalmente são divulgados quadros resumos do saldo de admissões e desligamentos por unidade federativa. Entretanto, boa parte das informações da CAGED não são divulgadas nesses quadros. Para obtê-las é necessário acessar o micro dados que são disponibilizados mensalmente na no ftp do MTE.
Nesse sentido, para realizar análises mais profundas sobre o mercado de trabalho se torna necessário saber manipular os micro dados da CAGED disponibilizados pelo MTE. Por essa razão resolvi escrever esse post. Vou usar os micro dados da CAGED referentes ao Distrito Federal no período de janeiro a dezembro de 2018 para:
- Obter saldo de emprego por RA e mês usando o
dplyr; - Usar os dicionários da CAGED para decodificar algumas variáveis;
- Representar o saldo de emprego em gráficos usando o
ggplot2.
Usando dplyr
Vamos carregar os micro dados da CAGED do ano de 2018 para o Distrito Federal. Em outros posts mostrarei como construir essa base. Ela está disponível no Github.
# Importando pacotes-----------------------------------------------------------------
rm(list = ls()) # Limpando workspace
library(dplyr)
library(ggplot2)
# Dados------------------------------------------------------------------------------
# Importando dados
load('dados/processado/caged df.RData')
dados <- dados_df
rm(dados_df)
# Variáveis contidas nos microdados
dados %>%
names()
[1] "Admitidos.Desligados" "Competência.Declarada" "Município"
[4] "Ano.Declarado" "CBO.2002.Ocupação" "CNAE.1.0.Classe"
[7] "CNAE.2.0.Classe" "CNAE.2.0.Subclas" "Faixa.Empr.Início.Jan"
[10] "Grau.Instrução" "Qtd.Hora.Contrat" "IBGE.Subsetor"
[13] "Idade" "Ind.Aprendiz" "Ind.Portador.Defic"
[16] "Raça.Cor" "Salário.Mensal" "Saldo.Mov"
[19] "Sexo" "Tempo.Emprego" "Tipo.Estab"
[22] "Tipo.Defic" "Tipo.Mov.Desagregado" "UF"
[25] "Regiões.Adm.DF" "Mesorregião" "Microrregião"
[28] "Periodo"
A base de dados possui 28 variáveis e 524 772 linhas. No momento, as variáveis de interesse são: Saldo.Mov, Regiões.Adm.DF e Periodo. Cada linha da base de dados se refere a uma admissão ou desligamento de um trabalhador. A variável Saldo.Mov reflete isso, caso ocorra uma admissão ela assume o valor 1, caso contrário -1. A variável Regiões.Adm.DF guarda o código numérico referente a cada Região Administrativa (RA) do Distrito Federal. Vamos dar uma olhada nessas variáveis.
# Estrutura dos dados
dados %>%
select(Regiões.Adm.DF, Periodo, Saldo.Mov) %>%
glimpse()
Observations: 524,772
Variables: 3
$ Regiões.Adm.DF <int> 3, 12, 12, 12, 12, 18, 17, 3, 3, 3, 3, 11, 12, 11, 1...
$ Periodo <date> 2018-01-01, 2018-01-01, 2018-01-01, 2018-01-01, 201...
$ Saldo.Mov <int> 1, 1, -1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
Agora, vamos obter o saldo de emprego por região administrativa usando o dplyr e salvá-lo em um data.frame. Assim, serão seguidos os seguintes passos para obter o resumo que queremos: 1) dizemos que queremos agregar o resumo por RA, 2) realizamos o operação de resumo e 3) salvamos o resumo no objeto saldo.ra.
# Saldo de emprego por RA
saldo.ra <- dados %>% # 3
group_by(Regiões.Adm.DF) %>% # 1
summarise(saldo = sum(Saldo.Mov)) # 2
# Salvando como data.frame e renomando coluna
saldo.ra <- data.frame(saldo.ra)
names(saldo.ra) <- c('reg_adm', 'saldo')
# Primeira linha do resumo
saldo.ra %>%
head()
reg_adm saldo
1 1 6720
2 2 432
3 3 676
4 4 600
5 5 -143
6 6 301
O inconveniente é que não temos o nome da RA no resumo, mas seu código. Vamos resolver isso mais à frente. Olhando o resultado acima podemos dizer que na RA 1, que é Brasília, foram gerados 6.720 empregos líquidos (admissões - desligamentos) em 2018. Já na RA 5, Paranoá, houve a encerramento líquido de 143 vagas de emprego formal.
Acima agrupamos o saldo de emprego por apenas uma variável, entretanto podemos agrupar o resumo por mais de uma variável. É o que faremos a seguir, vamos obter o saldo de emprego por RA e mês de 2018. Mas antes vamos obter o saldo de emprego por período.
# saldo por período
saldo.per <- dados %>%
group_by(Periodo) %>%
summarise(saldo = sum(Saldo.Mov))
saldo.per <- data.frame(saldo.per)
names(saldo.per) <- c('periodo', 'saldo')
# Saldo por RA e periodo
saldo.ra.per <- dados %>%
group_by(Regiões.Adm.DF, Periodo) %>%
summarise(saldo = sum(Saldo.Mov))
# Transformando em data.frame e renomeando
saldo.ra.per <- data.frame(saldo.ra.per)
names(saldo.ra.per) <- c('reg_adm', 'periodo', 'saldo')
# Primeiras linhas de saldo por RA e período
saldo.ra.per %>%
head()
reg_adm periodo saldo
1 1 2018-01-01 1114
2 1 2018-02-01 298
3 1 2018-03-01 561
4 1 2018-04-01 1329
5 1 2018-05-01 1413
6 1 2018-06-01 515
Usando dicionários
Já vimos como gerar os resumos a partir dos micro dados, agora vamos transformar o código referente ao nomes das RA’s em seus respectivos nomes.
O uso de código para representar o valor de determinadas variáveis é comum quando se trata de micro dados de pesquisas do IBGE ou outros órgãos semelhantes, como a Codeplan-DF, e etc. Há pelo menos duas razões por qual eles são usados: 1) certamente o código 01 ocupa menos espaço em memória do que Brasília e 2) é menos provável cometer um erro escrevendo 01 do que escrever Brasília na hora de compilar a pesquisa, já que neste último caso qualquer caractere diferente leva a uma informação diferente.
Uma forma de transformar o código no valor representado por ele é usando a função factor(). Entretanto, é necessário possuir um arquivo que mostre a relação entre o código numérico e o valor da variável representado por ele. Em geral, esse tipo de arquivo é chamado de dicionário. No caso da CAGED, é disponibilizado um arquivo Excel separado dos micro dados no qual estão todos os dicionários das variáveis da pesquisa.
Assim, vamos usar um dicionário para obter o nome das RA’s a partir do código numérico. O dicionário está disponível no Github.
# Importando dicionário
dic.ra <- read.delim("dados/dicionarios/regioes adminstrativas df.csv", sep = '\t')
# Decodificando Saldo.ra
saldo.ra$reg_adm <- factor(saldo.ra$reg_adm, levels = dic.ra$codigo,
labels = dic.ra$regiao.adm)
saldo.ra %>%
head()
reg_adm saldo
1 BRASILIA 6720
2 CRUZEIRO 432
3 GUARA 676
4 LAGO NORTE 600
5 PARANOA -143
6 LAGO SUL 301
# Decodificando Saldo.ra.per
saldo.ra.per$reg_adm <- factor(saldo.ra.per$reg_adm, levels = dic.ra$codigo,
labels = dic.ra$regiao.adm)
saldo.ra.per %>%
head()
reg_adm periodo saldo
1 BRASILIA 2018-01-01 1114
2 BRASILIA 2018-02-01 298
3 BRASILIA 2018-03-01 561
4 BRASILIA 2018-04-01 1329
5 BRASILIA 2018-05-01 1413
6 BRASILIA 2018-06-01 515
Usando ggplot2
Agora que já obtemos os saldo de emprego por RA, por período e por RA e período vamos visualizá-los com o pacote ggplot2. Inicialmente vamos construir um gráfico de barras para visualizar o saldo de emprego por RA.
# Gráfico saldo por RA
saldo.ra %>%
ggplot(aes(x = reorder(reg_adm, -saldo), y = saldo))+
geom_col(fill = 'steelblue')+
labs(x = '',
y = 'Saldo de emprego',
title = 'Saldo de emprego por RA em 2018',
caption = 'Fonte: CAGED/MTE')+
theme(axis.text.x = element_text(angle = 90, hjust = 1))
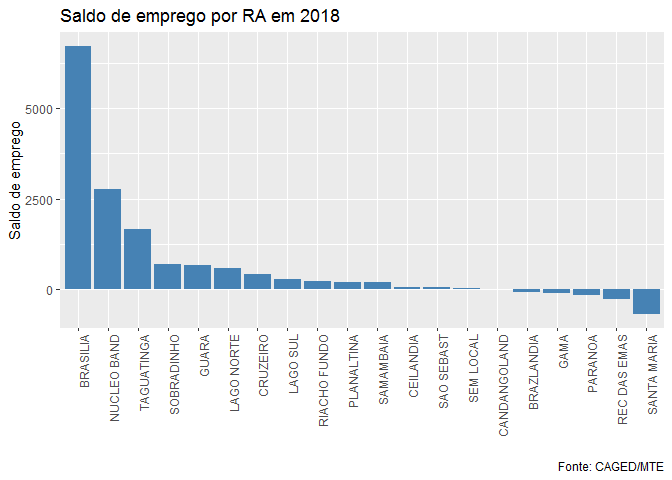
Como podemos ver Brasília, Núcleo Bandeirante e Taguatinga foram as três RA’s que mais criaram empregos líquidos em 2018. Já Santa Maria, Recanto da Emas e Paranoá foram as que apresentaram maior encerramento líquido de vagas formais de emprego.
Outra questão de interesse é a evolução do saldo de emprego ao longo do ano de 2018. Para tanto, vamos construir uma gráfico de linhas.
# Evolução do saldo de emprego
saldo.per %>%
ggplot(aes(x = periodo, y = saldo))+
geom_point(color = 'steelblue')+
geom_line(color = 'steelblue')+
geom_abline(slope = 0, linetype = 2)+
labs(x = '',
y = 'Saldo de emprego',
title = 'Evolução do saldo de emprego em 2018 no DF',
caption = 'Fonte: CAGED/MTE')
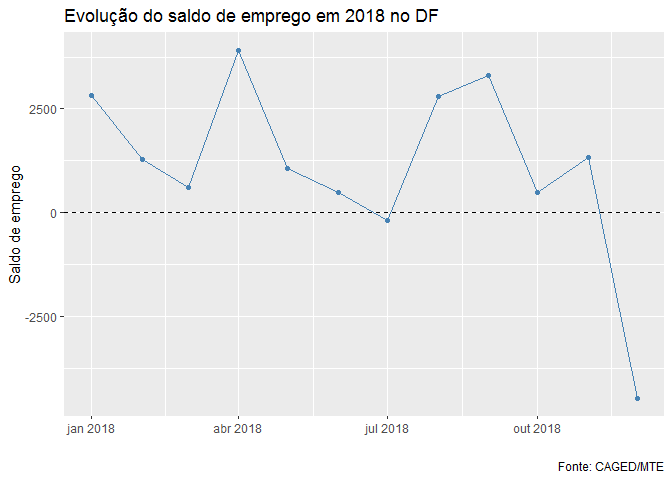
Com exceção de julho e dezembro, todos os meses apresentaram geração líquida de emprego com destaque para abril e setembro. Seria interessante saber como foi a evolução do saldo de emprego nas cidades que tiveram melhor desempenho. Assim, vamos construir um gráfico de linhas que mostra a evolução do saldo para as três RA’s que tiveram melhor desempenho na geração líquida de emprego.
Para fazer isso, vamos primeiro filtrar as regiões de interesse usando a função filter() do pacote dplyr e em seguida usar o ggplot2 para gerar os gráficos.
# Evolução do saldo de empregos nas RA's mais expressivas
saldo.ra.per %>%
filter(reg_adm %in% c('BRASILIA', 'NUCLEO BAND', 'TAGUATINGA')) %>%
ggplot(aes(x = periodo, y =saldo, color = reg_adm, shape = reg_adm))+
geom_point()+
geom_line()+
geom_abline(slope = 0, linetype = 2)+
labs(x = '',
y = 'Saldo de emprego',
title = "Evolução do saldo nas RA's de destaque",
caption = 'Fonte: CAGED/MTE',
color = '', shape = '')+
theme(legend.position = 'bottom')
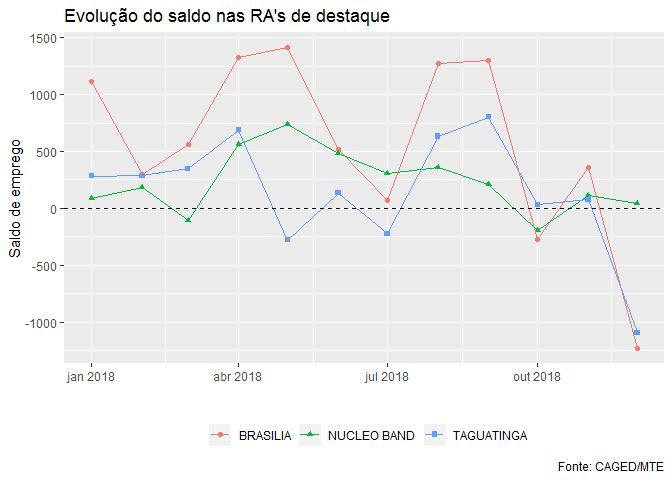
A evolução do saldo de emprego em Taguatinga é semelhante ao observado em Brasília, uma possível razão para isso seria se as atividades que mais geraram empregos líquidos fossem semelhantes em ambas as regiões. Por outro lado, no Núcleo Bandeirante, a evolução do saldo tem comportamento diverso, o que poderia indicar que atividades diferentes das de Taguatinga e Brasília impulsionaram a geração de empregos líquidos nessa região.
Para corroborar ou descartar essas hipóteses será necessário fazer um resumo de saldo de emprego por região administrativa e atividade. Porém, isso ficará para o próximo post.
Written on January 26th, 2020 by Neuremberg